AI Data Services
Purpose-Built Data for AI Teams. Secure by Design. No Lock-In.
Built for AI teams that require reliable, high-quality training data at scale
Data security, quality standards, and delivery requirements are defined before production begins
Transcription, annotation, translation, speech collection, and custom data services are delivered through structured workflows, controlled access procedures, and multi-tier quality review processes. Every project is aligned to client requirements from intake through final delivery.


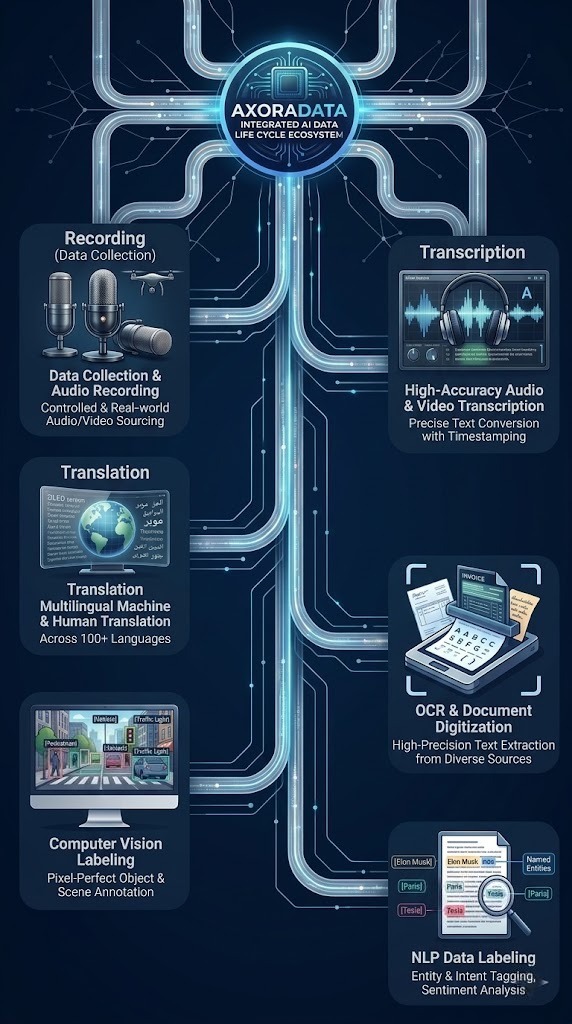
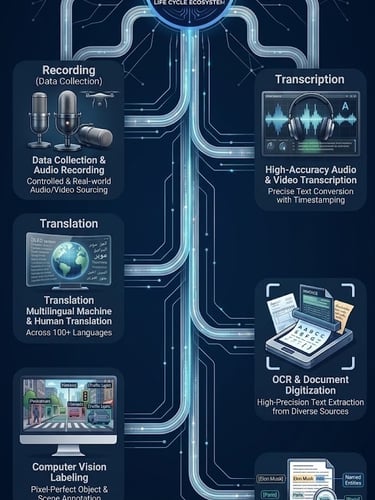
Our Core Modalities
Every modality, contractually specified
High-Accuracy Transcription
99%+ accuracy on domain-specific audio. Medical, legal, and technical vocabularies handled via custom language models with full timestamp and speaker diarization.
Expert Data Annotation
Computer vision and NLP annotation with full audit trails per task. Every label traceable to annotator, timestamp, and review state.
Multilingual Translation
50+ language pairs with native-speaker QA. Edge-case linguistic coverage built into the contract scope, not treated as out-of-scope incidents.
Custom Data Collection
Consent-managed, edge-case sourcing for training sets that commodity providers cannot supply. Collection spec signed before any data moves.
Custom Audio Sourcing
Custom audio collection of scripted phrases and spontaneous conversations. Sourced exclusively from native speakers across multiple languages to deliver high-fidelity training data for precise model iteration.
OCR & Document Digitization
High-precision text extraction and layout analysis for complex, unstructured documents. Specialized pipelines for handwritten and printed texts, governed by strict spatial accuracy specs for financial, medical, and legal records.
Production numbers, not projections
Evaluate Axoradata
An engineer reviews your spec, not a sales rep
Submit your data type, volume, and timeline. We assess feasibility against our accuracy and residency constraints before any engagement begins.